【データ加工画面】 #
データの欠損値補完やデータの数値変換を行う。
・ゼロ値補完
欠損しているデータに対して、その全てを0で置き換えます。
・平均値補完
欠損しているデータに対して、その全てを欠損していないデータの平均値で置き換えます。
・中央値補完
欠損しているデータに対して、その全てを欠損していないデータの中央値で置き換えます。
・最頻値補完
欠損しているデータに対して、その全てを欠損していないデータの平均値で置き換えます。
・欠損データ削除
欠損しているデータの含まれる行を削除します。
・再帰的多変量補完
欠損しているデータに対して、欠損していないデータからRidge回帰手法によりモデルを構築し、再帰的に欠損データを推定します。
・Quantile Transformation
分位点変換により、データ点が一様分布に従って並ぶように変換を行います。
・Log
データの対数をとります。
・Log1P
データに1を加えてから対数をとります。
【データのスケーリング画面】 #
入力・出力データのスケーリングを行う。
データのスケーリングは下記の式で行うが、スケーリングの方法によってa, bの数値が異なる。
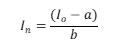
In: 規格化された数値
Io: オリジナルの数値
・Normalization
一般的な規格化の手法
a: Ioの平均
b: Ioの標準偏差
・Min-Max
データにおける最大値と最小値を使ってスケーリングを行う
a: Ioの最小値Imin
b: Ioの最大値Imax -最小値Imin
・Abs-max
データの絶対値の最大値を使ってスケーリングを行う
a: 0
b: Ioの絶対値の最大値|Imax |
・None
正規化処理を行わず、オリジナルの数値をそのまま用いる
【AI学習画面】 #
AIの学習を行うために、ニューラルネットワークの構造(ハイパーパラメータ)の設定を行う。
・Number of iteration
モデルを作成する数。ニューラルネットワークモデルでは、初期のネットワークの重みを乱数で与えるために、同じハイパーパラメータを設定しても毎回得られるモデルの精度が異なる。モデルを複数作成し、その平均的な誤差を調べることで、所定のハイパーパラメータにおけるニューラルネットワークの平均的な誤差を得ることができる。また、複数のモデルを用いたアンサンブル解析が可能となる。
・Number of outputs
アウトプットデータの数(変更不可)
・Number of epochs
訓練データを繰り返して学習させる数。数値が大きいほど、学習データに対するニューラルネットワークモデルの予測誤差が小さくなるが、大きすぎると過学習を招く
・Number of hidden layers
隠れ層の数
・Number of neurons of hidden layers
隠れ層のニューロン数
・Dropout of input layer
ニューラルネットワークの正則化手法のひとつで、学習時にユニットの出力を確率的に無視することで効率的に深い階まで学習を行う(入力層)
・Dropout of other layers
ニューラルネットワークの正則化手法のひとつで、学習時にユニットの出力を確率的に無視することで効率的に深い階まで学習を行う(入力層以外の層)
・Size of training data
機械学習モデルを構築する際に、AIの学習用データとして活用するデータのサイズ
・Size of batch
データセットを幾つかのサブセットに分けてAIを学習させる際に、サブセットに含まれるデータの数
・Number of patience
過学習を防ぐために学習を途中で打ち切る(Early stopping)ときの最小のepoch数
・Number of split
Early stoppingの判断を行うために分割するデータの割合
・Batch normalization
ニューラルネットワークの各層への入力を正規化する手法
・Activation function except output layer
出力層以外の層の活性化関数(各ノードへの入力値の合計を次の層への出力値に変換する関数)
・Activation function for output layer
出力層の活性化関数(出力層の各ノードへの入力値の合計を出力値に変換する関数)
・Check random
AIの学習を行う前に、学習データをランダムに入れ替える処理。これを行うことで、複数のモデルを作成する際に、毎回異なるtrainingデータで学習させることができ、検証データによる誤差の偏りを防ぐことができる。
・Loss function
損失関数。ニューラルネットワークの予測値と実際値の誤差の計算方法
・Optimizer
最適化手法。予測値と実際値の誤差を小さくするように各ノードの重みとバイアスを更新する方法
・Number of epochs when learning stopped
学習が終了するまでの訓練データの繰り返し数
・Cumulated distance between validation data
検証データ間の累積距離。値が大きいほど、検証データの多様性が高い。
・RMSE after preprocessing
スケーリング後のスケールでの二乗平均平方根誤差(RMSE)
・RMSE before preprocessing
スケーリング前のスケールに戻したときの二乗平均平方根誤差(RMSE)
・Relative error
相対誤差。Multi-Sigmaでは、Σ|(予測値 – 実測値)/実測値 |/予測データ数 で算出
・Correlation between prediction and actual
予測値と実際値の相関係数。1に近いほど正の相関、-1に近いほど負の相関、0に近いほど無相関を示す。
【AI予測画面】 #
AI学習によって作成したAIモデルを用いて、未知のインプットデータに対するアウトプットデータの予測を行う。
・アンサンブルモデル
複数の異なるモデルによるアウトプットの平均値を算出する。
【最適化画面】 #
AI学習によって作成したAIモデルと、多目的遺伝的アルゴリズムを用いて最適なアウトプットの条件となるインプットの探索を行う。
・Size of generation
最適解を探索するための世代数
・Size of population
各世代の個体の数
・Number of crossover rate
優れた解をもつ個体のペア(Parent)が遺伝子を交差する割合
・Number of mutation rate
各世代の優れた個体が突然変異する割合
・Ratio of elite
解析結果として出力される、各世代において保存される優れた個体の割合・Scale factor:
個体の多様性を確保するために、アウトプットが近い個体を排除する強さを設定するパラメータ。数値が大きくなるほどアウトプットの近い個体を排除する。



