- AIモデル数(Number of AI models):
- 出力パラメータ数(Number of output parameters):
- Epoch数(Number of epochs):
- 隠れ層の数(Number of hidden layers):
- 隠れ層のニューロン数(Number of neurons of hidden layers):
- 入力層のドロップアウト率(Dropout rate of the input layer):
- 入力層以外の層のドロップアウト率(Dropout rate expet for the input layer):
- 学習データの数(Size of training data):
- バッチサイズ(Size of batch):
- Early stopping におけるPatience(Number of patience in early stopping):
- Early stopping における検証データの比率(Validation set ratio in ealry stopping):
- バッチ正規化(Batch normalization):
- 最適化関数(Optimizer):
- 学習率:
- 出力層以外の活性化関数(Activation function except the output layer):
- 出力層の活性化関数(Activation function for the output layer):
- 検証データの抽出(Extraction of validation data):
AIの学習を行うために、ニューラルネットワークの構造(ハイパーパラメータ)の設定を行います。
AIモデル数(Number of AI models): #
異なる初期値を用いて構築するAIモデルの数
出力パラメータ数(Number of output parameters): #
アウトプットデータの数(変更不可)
Epoch数(Number of epochs): #
訓練データを繰り返して学習させる数。値が大きいほど、学習データに対するニューラルネットワークモデルの予測誤差が小さくなりますが、大きすぎると過学習を招きます。
隠れ層の数(Number of hidden layers): #
入力層・出力層以外の層の数
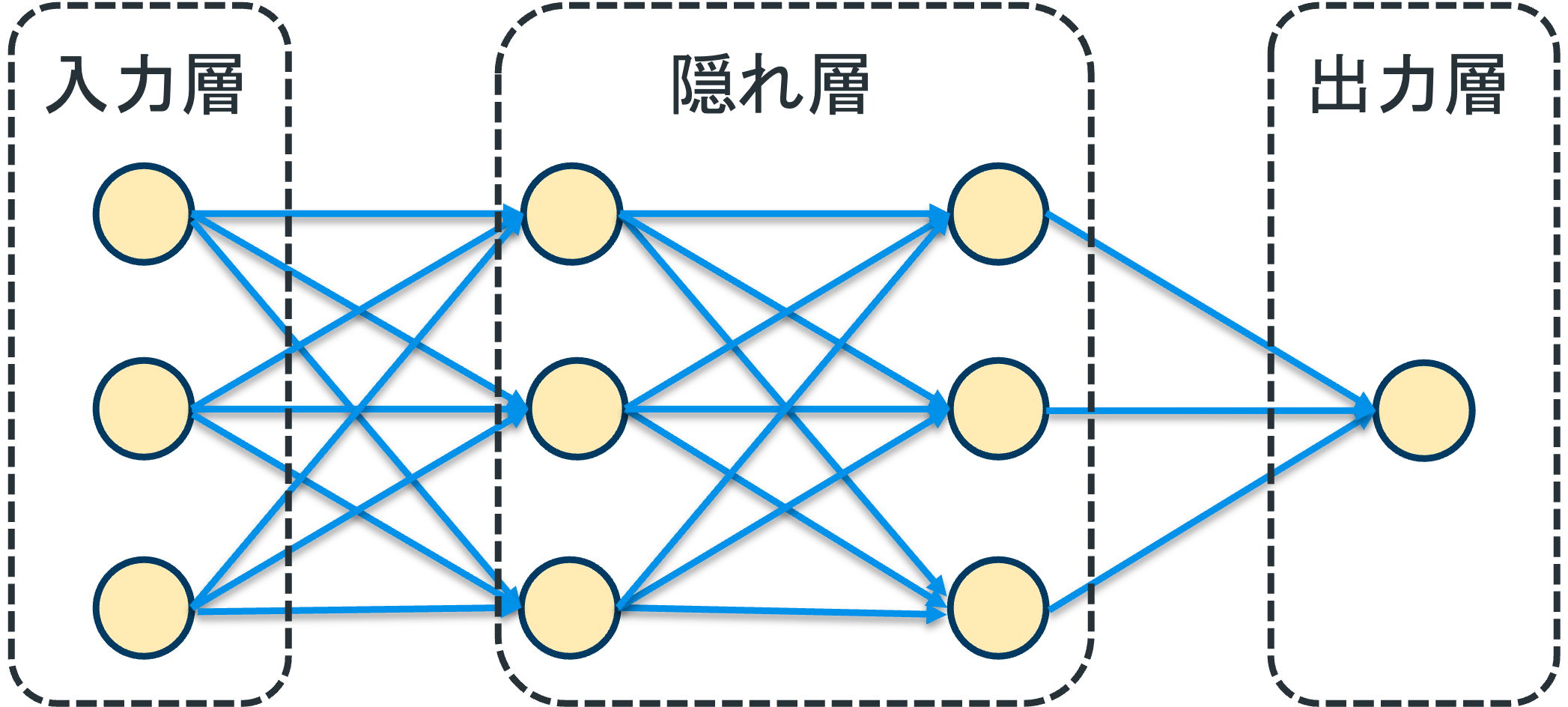
隠れ層のニューロン数(Number of neurons of hidden layers): #
隠れ層におけるニューロンの数
入力層のドロップアウト率(Dropout rate of the input layer): #
モデル学習中に、各入力ユニットをどのくらいの確率で一時的に無効化するかを表す値
入力層以外の層のドロップアウト率(Dropout rate expet for the input layer): #
モデル学習中に、隠れ層の各ユニットをどのくらいの確率で一時的に無効化するかを表す値
学習データの数(Size of training data): #
機械学習モデルを構築する際に、AIの学習用データとして活用するデータのサイズ
バッチサイズ(Size of batch): #
バッチサイズとは、データセットを小分けにして学習するときに、1回あたりの学習で使うデータ数
Early stopping におけるPatience(Number of patience in early stopping): #
過学習を防ぐために学習を途中で打ち切る(Early stopping)ときの最小のepoch数
Early stopping における検証データの比率(Validation set ratio in ealry stopping): #
Early stopping における検証データの比率とは、学習をいつ止めるかを判断するために使う検証データの割合
バッチ正規化(Batch normalization): #
ニューラルネットワークの各層への入力を正規化する手法
最適化関数(Optimizer): #
予測値と実際値の誤差が小さくなるように、モデルの重みやバイアスを更新する最適化手法
学習率: #
モデルが学習するときに、重みやバイアスを1回ごとにどの程度調整するかを表す値
出力層以外の活性化関数(Activation function except the output layer): #
各ノードへの入力値の合計を、そのノードの出力値に変換する関数
出力層の活性化関数(Activation function for the output layer): #
出力層の各ノードへの入力値の合計を最終的な出力値に変換する関数
検証データの抽出(Extraction of validation data): #
学習過程における検証データの抽出方法。「Random」は、学習データからランダムに検証データを選択する方法。「Balanced」は、学習データの偏りが少なくなるように、バランスよく検証データを選択する方法。「Last」は、学習データの最後の方に並んでいるデータを検証データとして選択する方法。



